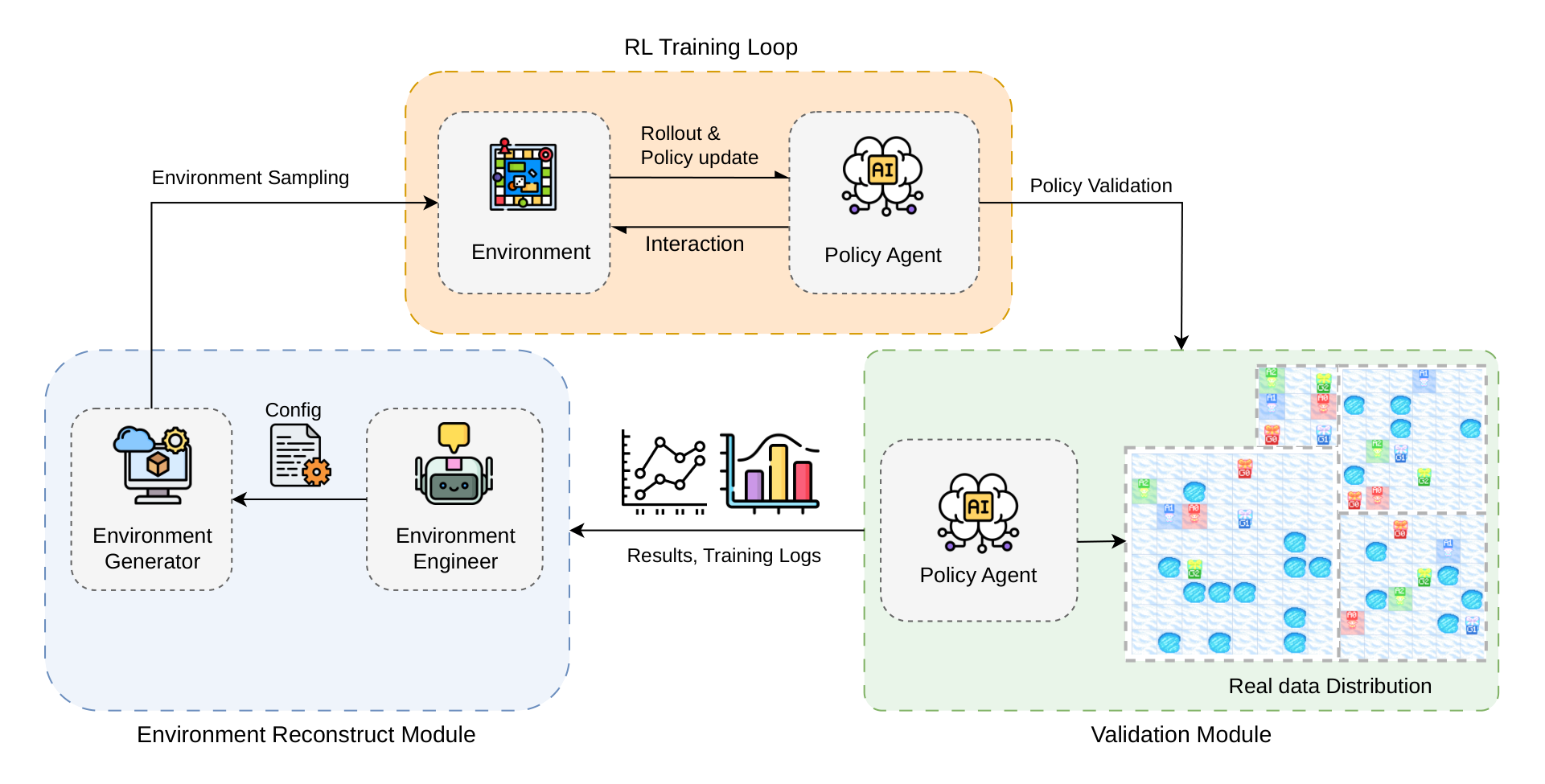
Abstract
Reinforcement learning pipelines for Large Language Model (LLM) training often rely on manually redesigned environments between stages, requiring practitioners to heuristically infer which configuration will best improve the current policy. To automate this process, we propose the LLM-as-Environment-Engineer framework in which the current policy model analyzes failure trajectories together with contextual information and proposes modifications to the next-stage training environment configuration.
We also introduce MAPF-FrozenLake, a controllable testbed whose generator exposes multi-dimensional environment configurations, making it suitable for studying and benchmarking environment redesign. On this testbed, we condition the environment engineer on structured summaries of policy behavior, failure cases, and environment statistics, from which it produces the configuration for the next training stage.
With Qwen3-4B as the backbone, our framework achieves the strongest aggregate performance on our benchmarks, outperforming larger proprietary LLMs (e.g., GPT, Gemini) and fixed-environment training baselines. We further analyze which forms of context are most effective, finding that successful environment updates rely on failure evidence and preserve configurations that already work. Interestingly, the current RL checkpoint serves as a better environment engineer than the original base model, suggesting that policy learning improves the model's ability to diagnose its remaining weaknesses.
Case Study
We probe the trained policy from two complementary angles: (1) a small board where the base model fails and the trained model recovers the optimal plan, and (2) a much harder out-of-distribution board that pushes every controllable axis — agent count, map size, and obstacle density — to its maximum.
Case 1 — From failure to success on a 3×3 board 2 agents
Both checkpoints receive the same prompt; we visualise the executed plan token-by-token. The base model emits an illegal/incomplete trajectory; the trained policy recovers the optimal makespan-2 solution while spending 12× fewer tokens.
Base Qwen3-4B
The base model parses the map and proposes an action for
Agent 0 but the trajectory for Agent 1 is incomplete, leaving an
illegal/incomplete plan. The evaluator flags
has_illegal_moves = true and
all_goals_reached = false.
Tokens generated: 7,464
- Valid✗
- Optimal✗

Trainee-to-Trainer (ours)
After three rounds of LLM-engineered curriculum, the same model finds the optimal plan in three timesteps: Agent 0 moves LEFT, DOWN, LEFT, Agent 1 moves UP, LEFT, LEFT, with no collisions and no illegal jumps.
Tokens generated: 622
- Valid✓
- Optimal✓

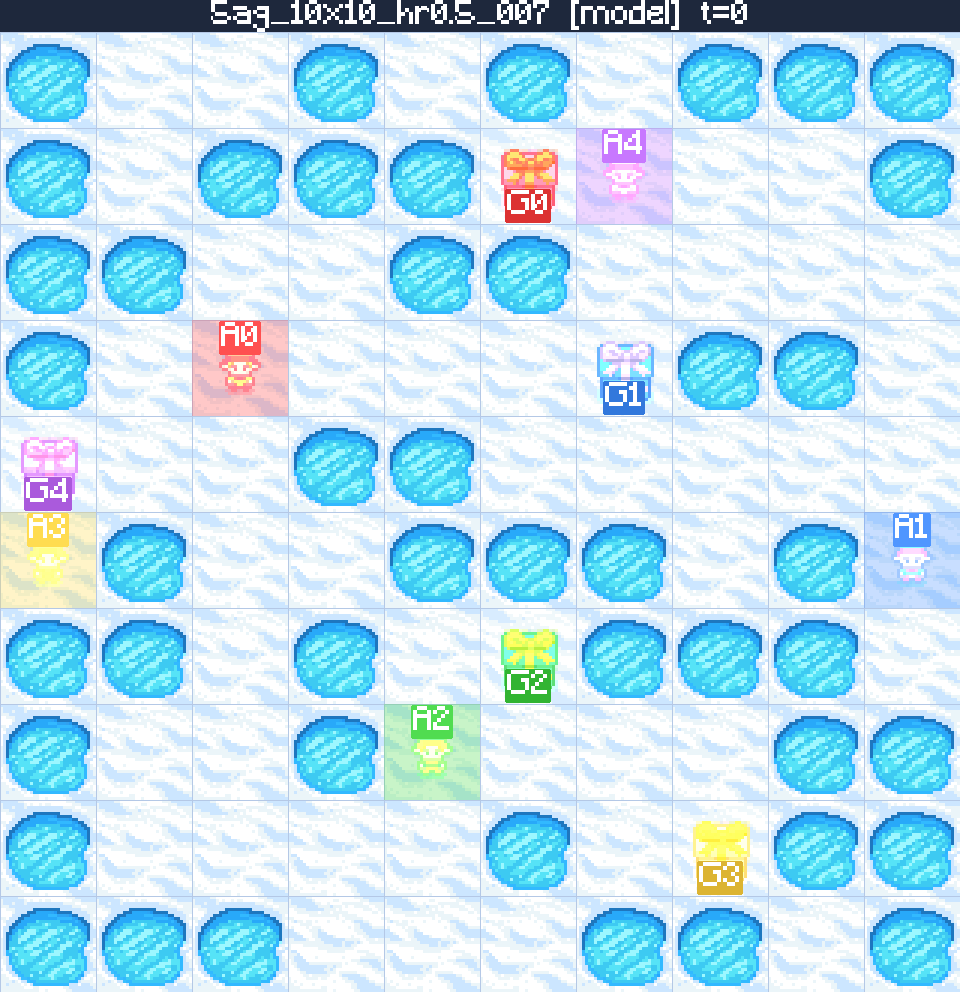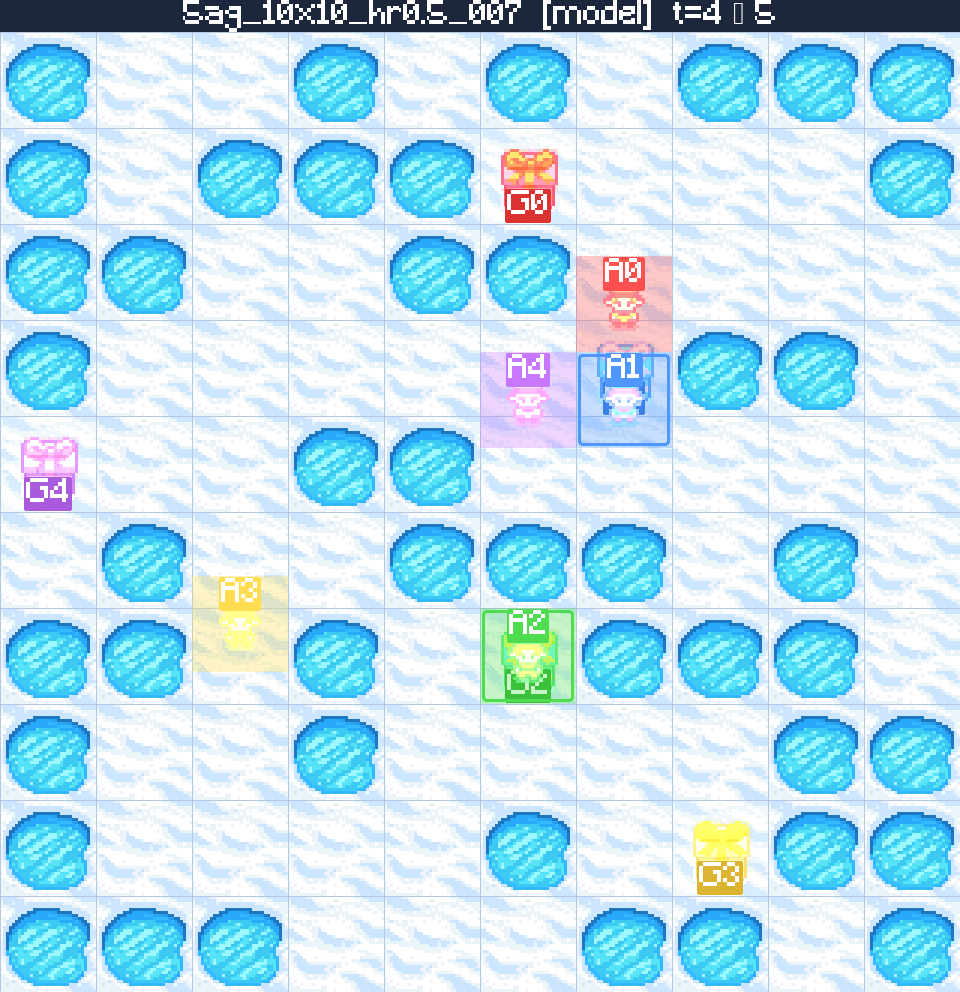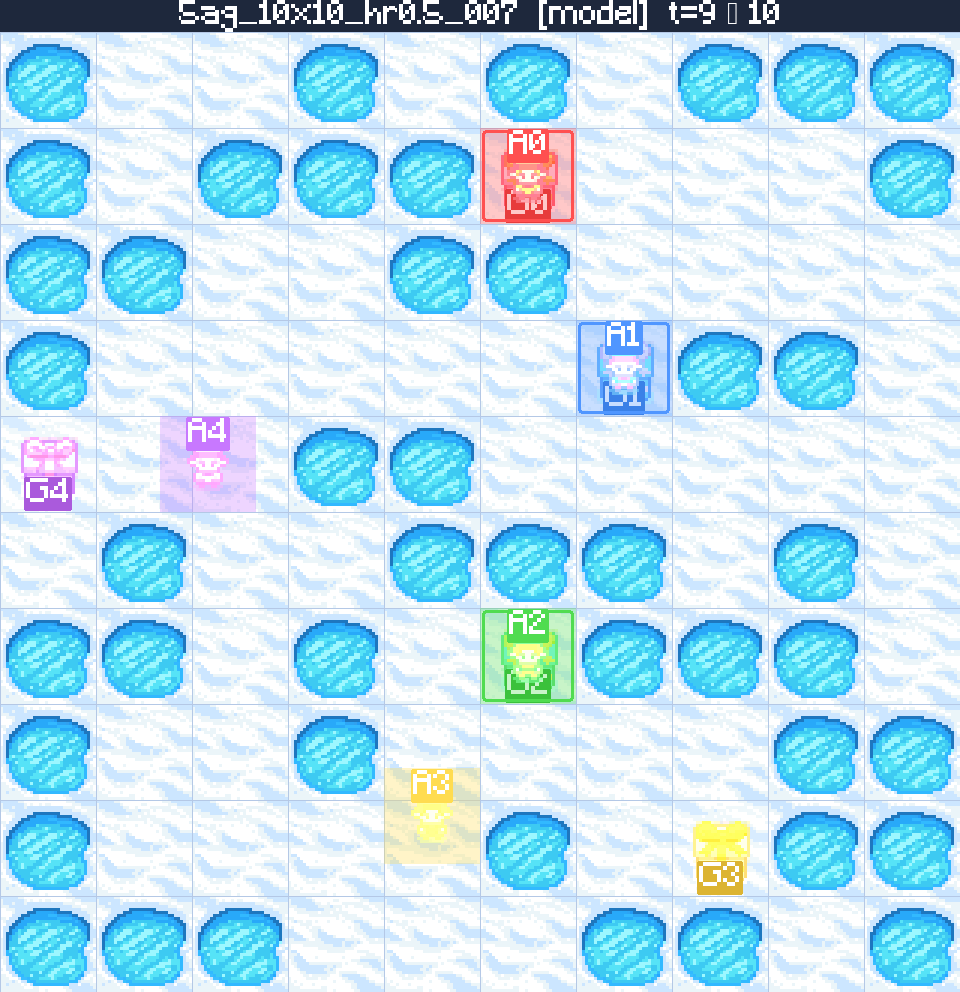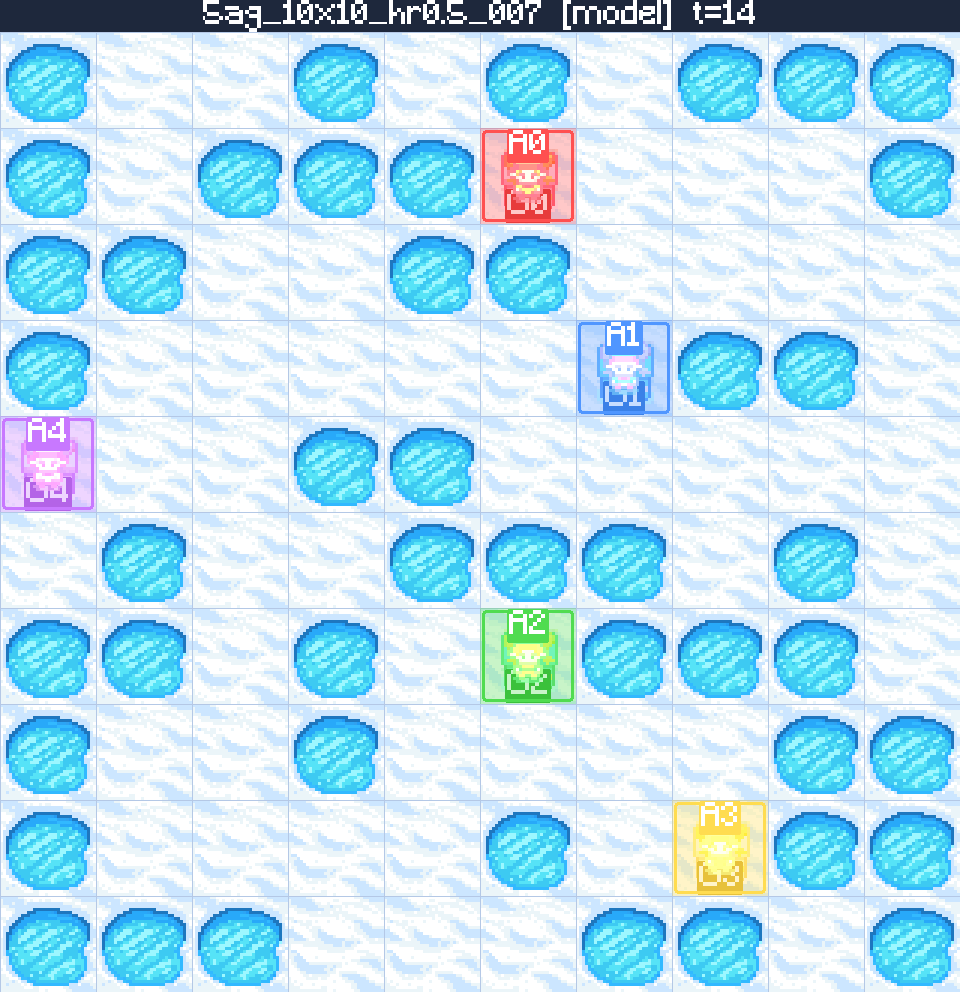
Case 2 — Generalising to a 10×10 maze 5 agents 50% holes
The model is trained exclusively on 2-agent boards, yet it generalises to the hardest setting our benchmark generator can produce: 5 agents, a 10×10 grid, and 50% obstacle density. The trained policy still returns a collision-free, makespan-optimal plan — evidence that the LLM-engineered curriculum teaches transferable MAPF skills rather than over-fitting to small boards.
Trainee-to-Trainer (ours)
Five colour-coded agents must reach their matching destinations on a 10×10 board littered with holes. The trained policy plans every agent's full trajectory in a single rollout — respecting vertex-, edge- and obstacle-constraints — and lands on the optimal makespan for the ground-truth solution.
Tokens generated: 3,512
- Agents5
- Map10×10
- Holes50%
- Valid✓
- Optimal✓
Experimental Results
Main results on the MAPF-FrozenLake benchmark across map sizes 3×3 to 10×10 and 3–5 agents. For each cell, acc. = valid rate (%) and opt. = optimal rate (%). Right-most Sum column reports the aggregate over all sizes. Bold = best in column.
| Model | 3×3 | 4×4 | 5×5 | 6×6 | 7×7 | 8×8 | 9×9 | 10×10 | Sum | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | |
| GPT-5.4 | 64.67 | 41.33 | 44.67 | 29.33 | 42.67 | 31.33 | 28.00 | 16.00 | 20.67 | 12.67 | 26.67 | 15.33 | 20.00 | 11.31 | 12.67 | 7.33 | 32.50 | 20.58 |
| Grok-4.2 | 36.00 | 25.33 | 50.00 | 37.33 | 29.33 | 18.67 | 35.33 | 21.33 | 29.33 | 12.00 | 36.67 | 21.33 | 36.00 | 22.00 | 14.67 | 10.00 | 33.42 | 21.00 |
| Gemini-3.1-Pro | 45.33 | 33.33 | 32.67 | 23.33 | 35.33 | 20.00 | 24.00 | 12.00 | 18.67 | 9.33 | 20.00 | 10.67 | 12.00 | 9.33 | 8.00 | 4.67 | 24.50 | 15.33 |
| Kimi-K2.5 | 66.00 | 43.33 | 59.33 | 34.67 | 57.33 | 34.00 | 47.33 | 34.67 | 38.00 | 22.67 | 41.33 | 24.00 | 36.67 | 24.67 | 23.33 | 16.00 | 46.17 | 29.25 |
| Qwen3-4B (base) | 40.00 | 38.00 | 24.00 | 21.33 | 18.00 | 16.67 | 10.67 | 10.67 | 8.00 | 8.00 | 5.33 | 4.67 | 10.00 | 10.00 | 2.67 | 2.67 | 14.83 | 14.00 |
| Qwen3-4B + GRPO (random) | 54.67 | 41.33 | 54.00 | 40.67 | 50.67 | 29.33 | 42.67 | 26.00 | 38.67 | 21.33 | 30.67 | 18.00 | 32.67 | 18.67 | 19.33 | 13.33 | 40.42 | 26.08 |
| Qwen3-4B + GRPO + Ours | 68.67 | 48.00 | 64.67 | 41.33 | 62.67 | 35.33 | 52.67 | 37.33 | 46.00 | 26.00 | 42.67 | 24.00 | 44.00 | 25.33 | 32.00 | 16.00 | 51.67 | 31.67 |
| Model | 4×4 | 5×5 | 6×6 | 7×7 | 8×8 | 9×9 | 10×10 | Sum | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | |
| GPT-5.4 | 35.33 | 22.00 | 24.00 | 16.00 | 16.00 | 10.00 | 14.00 | 9.33 | 16.67 | 10.67 | 9.33 | 5.33 | 4.00 | 2.67 | 17.05 | 10.86 |
| Grok-4.2 | 48.00 | 34.00 | 30.00 | 21.33 | 32.00 | 18.00 | 25.33 | 16.67 | 5.33 | 3.33 | 8.67 | 6.67 | 14.67 | 7.33 | 23.43 | 15.33 |
| Gemini-3.1-Pro | 28.67 | 22.67 | 16.67 | 14.67 | 12.67 | 10.67 | 16.67 | 12.67 | 8.67 | 5.33 | 4.67 | 2.00 | 3.33 | 2.67 | 12.95 | 10.10 |
| Kimi-K2.5 | 44.67 | 28.67 | 35.33 | 20.67 | 28.67 | 16.67 | 28.00 | 22.67 | 22.00 | 16.67 | 20.67 | 14.00 | 9.33 | 6.00 | 26.95 | 17.90 |
| Qwen3-4B (base) | 10.67 | 9.33 | 4.67 | 4.00 | 2.67 | 2.67 | 4.00 | 3.33 | 2.00 | 2.00 | 0.00 | 0.00 | 0.00 | 0.00 | 3.43 | 3.05 |
| Qwen3-4B + GRPO (random) | 42.67 | 27.33 | 33.33 | 23.33 | 31.33 | 18.67 | 26.67 | 15.33 | 19.33 | 12.00 | 19.33 | 10.67 | 14.00 | 5.33 | 26.67 | 16.10 |
| Qwen3-4B + GRPO + Ours | 49.33 | 32.00 | 37.33 | 25.33 | 36.67 | 22.00 | 33.33 | 24.67 | 31.33 | 20.67 | 25.33 | 16.67 | 18.67 | 8.00 | 33.14 | 21.33 |
| Model | 5×5 | 6×6 | 7×7 | 8×8 | 9×9 | 10×10 | Sum | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | acc. | opt. | |
| GPT-5.4 | 17.33 | 14.00 | 10.00 | 6.00 | 10.00 | 4.00 | 6.00 | 4.67 | 5.33 | 4.00 | 6.00 | 3.33 | 9.11 | 6.00 |
| Grok-4.2 | 26.67 | 16.00 | 13.33 | 9.33 | 16.67 | 10.67 | 6.67 | 6.00 | 7.33 | 5.33 | 6.67 | 5.33 | 12.89 | 8.78 |
| Gemini-3.1-Pro | 9.33 | 8.00 | 6.67 | 4.67 | 5.33 | 4.00 | 4.67 | 3.33 | 2.00 | 1.33 | 0.67 | 0.00 | 4.78 | 3.56 |
| Kimi-K2.5 | 23.33 | 17.33 | 18.00 | 12.00 | 16.00 | 7.33 | 14.00 | 8.67 | 8.00 | 4.67 | 6.00 | 2.67 | 13.47 | 8.78 |
| Qwen3-4B (base) | 2.67 | 2.00 | 2.67 | 2.67 | 0.67 | 0.00 | 2.00 | 2.00 | 0.67 | 0.67 | 0.00 | 0.00 | 1.44 | 1.22 |
| Qwen3-4B + GRPO (random) | 24.00 | 16.67 | 21.33 | 14.00 | 16.00 | 10.00 | 13.33 | 8.00 | 8.67 | 2.67 | 7.33 | 3.33 | 15.11 | 9.11 |
| Qwen3-4B + GRPO + Ours | 28.00 | 18.00 | 26.00 | 17.33 | 22.00 | 12.00 | 18.00 | 10.67 | 10.00 | 2.67 | 8.00 | 5.33 | 18.67 | 11.00 |